Gerou uma imagem de IA de difusão estável, mas não é bem o que você quer? Neste artigo, vou lhe ensinar algumas técnicas simples de prompt para que você possa discar suas imagens.
Um dos usos mais populares do Stable Diffusion é gerar pessoas realistas. Elas podem parecer tão reais quanto tiradas de uma câmera. Nesta publicação, você aprenderá a mecânica de gerar imagens de retratos no estilo de fotos. Você aprenderá sobre prompts, modelos e upscalers para gerar pessoas realistas.
Stable Diffusion WebUI (AUTOMATIC1111 ou A1111 para abreviar) é a GUI de fato para usuários avançados. Graças à comunidade apaixonada, a maioria dos novos recursos vêm primeiro para esta GUI gratuita do Stable Diffusion. Mas não é o software mais fácil de usar. Falta documentação. A extensa lista de recursos que ele oferece pode ser intimidante.
Este guia lhe ensinará como usar a GUI AUTOTMATIC1111. Você pode usá-lo como um tutorial. Há muitos exemplos que você pode seguir passo a passo.
Você também pode usar este guia como um manual de referência . Pule-o e veja o que há lá. Volte a ele quando realmente precisar usar um recurso.
Você verá muitos exemplos para demonstrar o efeito de uma configuração, porque acredito que essa é a única maneira de deixá-la clara.
Stable Diffusion XL (SDXL) é o mais recente modelo de imagem de IA que pode gerar pessoas realistas, texto legível e diversos estilos de arte com excelente composição de imagem. É uma versão maior e melhor do celebrado modelo Stable Diffusion v1.5 , e daí o nome SDXL.
Desenvolver um processo para construir bons prompts é o primeiro passo que todo usuário do Stable Diffusion enfrenta. Este artigo resume o processo e as técnicas desenvolvidas por meio de experimentações e contribuições de outros usuários. O objetivo é escrever tudo o que sei sobre prompts para que você possa conhecê-los todos em um só lugar.
Não importa quão bons sejam seu prompt e modelo, é raro obter uma imagem perfeita em uma única foto.
Inpainting é uma maneira indispensável de consertar pequenos defeitos. Neste post, vou passar por alguns exemplos básicos de uso de inpainting para consertar defeitos.
Se você é novo em imagens de IA, talvez seja interessante ler primeiro o guia para iniciantes.
É uma boa imagem, mas gostaria de corrigir os seguintes problemas
O rosto parece artificial.
O braço direito está faltando.
Use um modelo Inpainting – Pintura Interna (opcional)
Você sabia que existe um modelo de Difusão Estável treinado para inpainting? Você pode usá-lo se quiser obter o melhor resultado. Mas, normalmente, é OK usar o mesmo modelo com o qual você gerou a imagem para inpainting.
Para instalar o modelo de pintura v1.5 , baixe o arquivo de ponto de verificação do modelo e coloque-o na pasta
stable-diffusion-webui/models/Stable-diffusion
No AUTOMATIC1111, pressione o ícone de atualização ao lado da caixa suspensa de seleção de ponto de verificação no canto superior esquerdo. Selecione sd-v1-5-inpainting.ckptpara habilitar o modelo.
Criando uma máscara de pintura
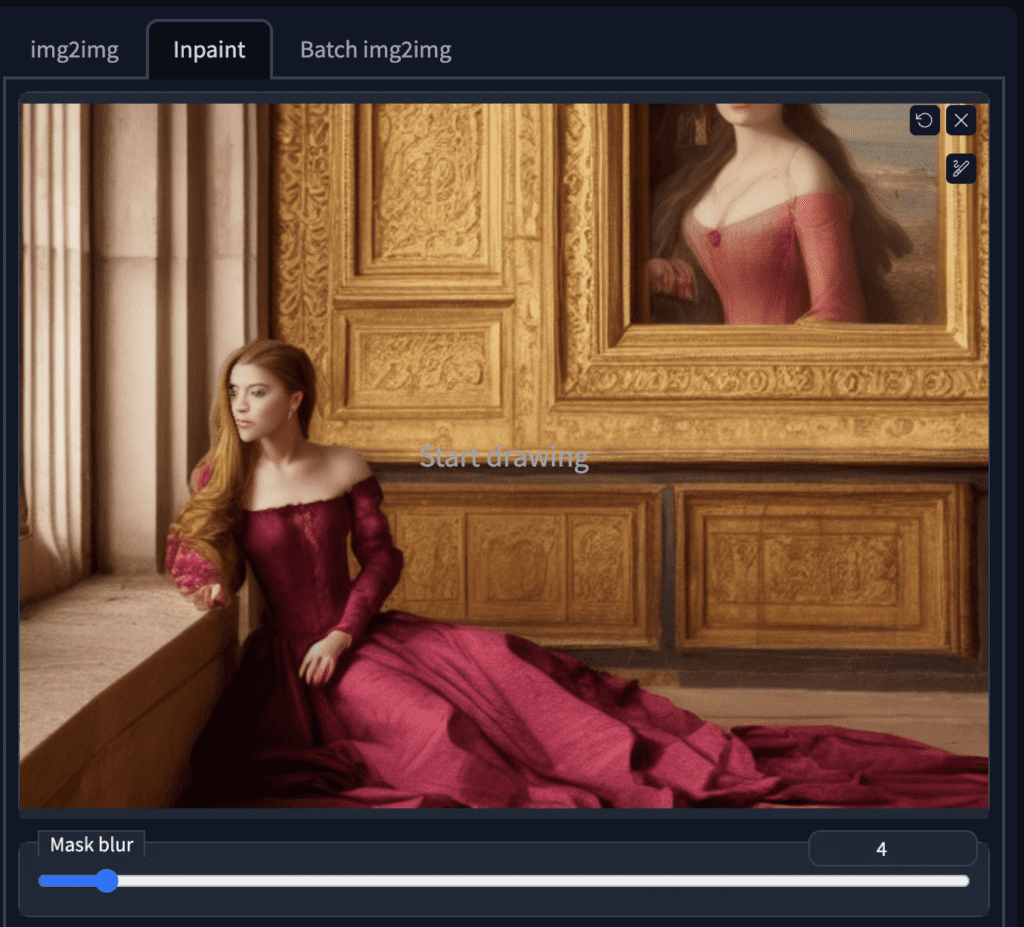
Na GUI do AUTOMATIC1111, selecione a aba img2img e selecione a subaba Inpaint . Carregue a imagem para a tela inpainting.
inpainting
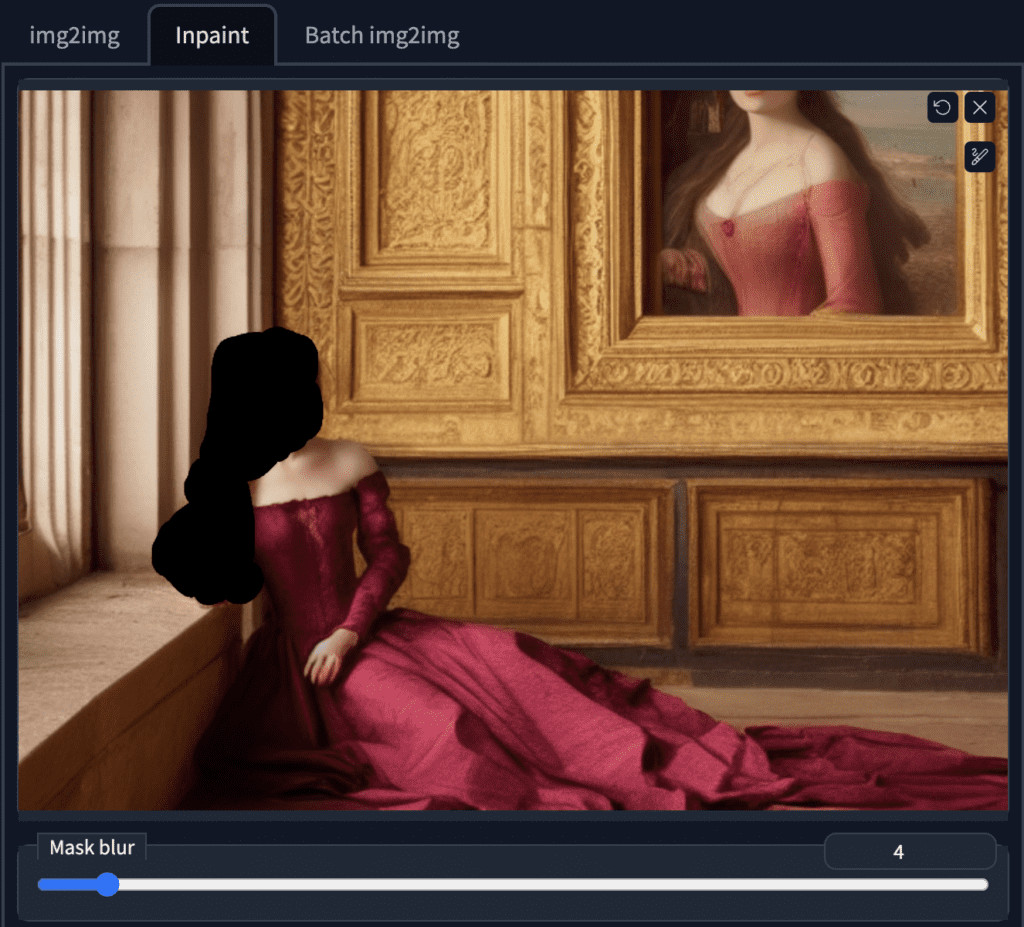
Vamos pintar o braço direito e o rosto ao mesmo tempo. Use a ferramenta pincel para criar uma máscara . Esta é a área em que você quer que o Stable Diffusion regenere a imagem.
Crie uma máscara usando a ferramenta pincel
Configurações para pintura interna
Prompt
Você pode reutilizar o prompt original para corrigir defeitos. Isso é como gerar múltiplas imagens, mas apenas em uma área específica.
Tamanho da imagem
O tamanho da imagem precisa ser ajustado para ser o mesmo da imagem original. (704 x 512 neste caso).
Restauração facial
Se você estiver pintando rostos, você pode ativar a restauração de rostos . Você também precisará selecionar e aplicar o modelo de restauração de rosto a ser usado na aba Configurações . O CodeFormer é um bom.
Cuidado, pois esta opção pode gerar visuais não naturais. Também pode gerar algo inconsistente com o estilo do modelo.
Conteúdo da máscara
A próxima configuração importante é Conteúdo da Máscara .
Selecione original se quiser que o resultado seja guiado pela cor e forma do conteúdo original. Original é frequentemente usado ao pintar rostos porque a forma geral e a anatomia estavam ok. Queremos apenas que pareça um pouco diferente.
Na maioria dos casos, você usará o Original e alterará a intensidade da redução de ruído para obter efeitos diferentes.
Você pode usar latent noise ou latent nothing se quiser regenerar algo completamente diferente do original, por exemplo, remover um membro ou esconder uma mão. Essas opções inicializam a área mascarada com algo diferente da imagem original. Ela produzirá algo completamente diferente.
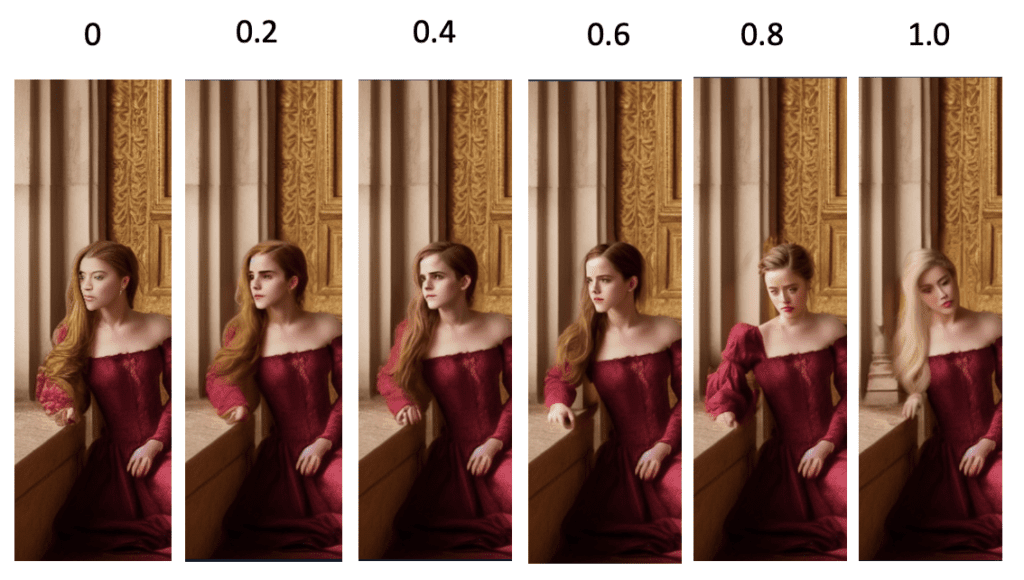
Força de redução de ruído
A intensidade do denoising controla quanta mudança ele fará em comparação com a imagem original. Nada mudará quando você definir como 0. Você obterá uma pintura interna não relacionada quando definir como 1.
0,75 geralmente é um bom ponto de partida. Diminua se quiser mudar menos.
Tamanho do lote
Certifique-se de gerar algumas imagens por vez para que você possa escolher as melhores. Defina a semente para -1 para que cada imagem seja diferente.
Prompt
(Igual ao original)
Etapas de amostragem
20
Seed
-1
Tamanho da imagem
704 x 512
Restauração facial
Codeformer
Método de amostragem
Euler a
Modelo
Stable Diffusion v1.5 inpainting
Conteúdo da máscara
ruído latente ou nada latente
Inpaint em resolução máxima
On
Força de redução de ruído
0,75
Resultados de pintura interna
Abaixo estão algumas das imagens com inpainted aplicado.
inpainted aplicado
Mais uma rodada de inpainted – pintura interna
Gosto do último, mas há uma mão extra sob o braço recém-pintado. Siga etapas semelhantes de upload desta imagem e criação de uma máscara. O conteúdo mascarado deve ser definido como ruído latente para gerar algo completamente diferente.
A mão sob o braço é removida com a segunda rodada de pintura:
Use a pintura interna para remover a mão extra sob o braço
E esta é minha imagem final.
Uma comparação lado a lado
Esquerda: original. Direita: repintado 2 vezes.
Inpainting é um processo iterativo. Você pode aplicá-lo quantas vezes quiser para refinar uma imagem.
Veja esta postagempara outro exemplo mais extremo de inpainting.
Adicionar novos objetos ao prompt original garante consistência no estilo. Você pode ajustar o peso da palavra-chave (1.2 acima) para fazer o leque aparecer.
Defina o conteúdo mascarado como ruído latente .
Ajuste a intensidade da redução de ruído e a escala CFG para refinar as imagens pintadas.
Depois de alguma experimentação, nossa missão foi cumprida:
Adding a hand fan with inpainting.
Explicação dos parâmetros de pintura interna
Força de redução de ruído
A intensidade do denoising controla o quanto a imagem final deve respeitar o conteúdo original. Definindo como 0 não muda nada. Definindo como 1, você tem uma imagem não relacionada.
Defina um valor baixo se quiser uma pequena mudança e um valor alto se quiser uma grande mudança.
Alterando a intensidade do denoising. Defina um valor baixo se quiser uma mudança pequena e um valor alto se quiser uma mudança grande.
Escala CFG
Semelhante ao uso em texto para imagem , a escala de Orientação Livre do Classificador é um parâmetro para controlar o quanto o modelo deve respeitar seu prompt.
1 – Ignore principalmente seu prompt. 3 – Seja mais criativo. 7 – Um bom equilíbrio entre seguir o prompt e a liberdade. 15 – Aderir mais ao prompt. 30 – Siga o prompt rigorosamente.
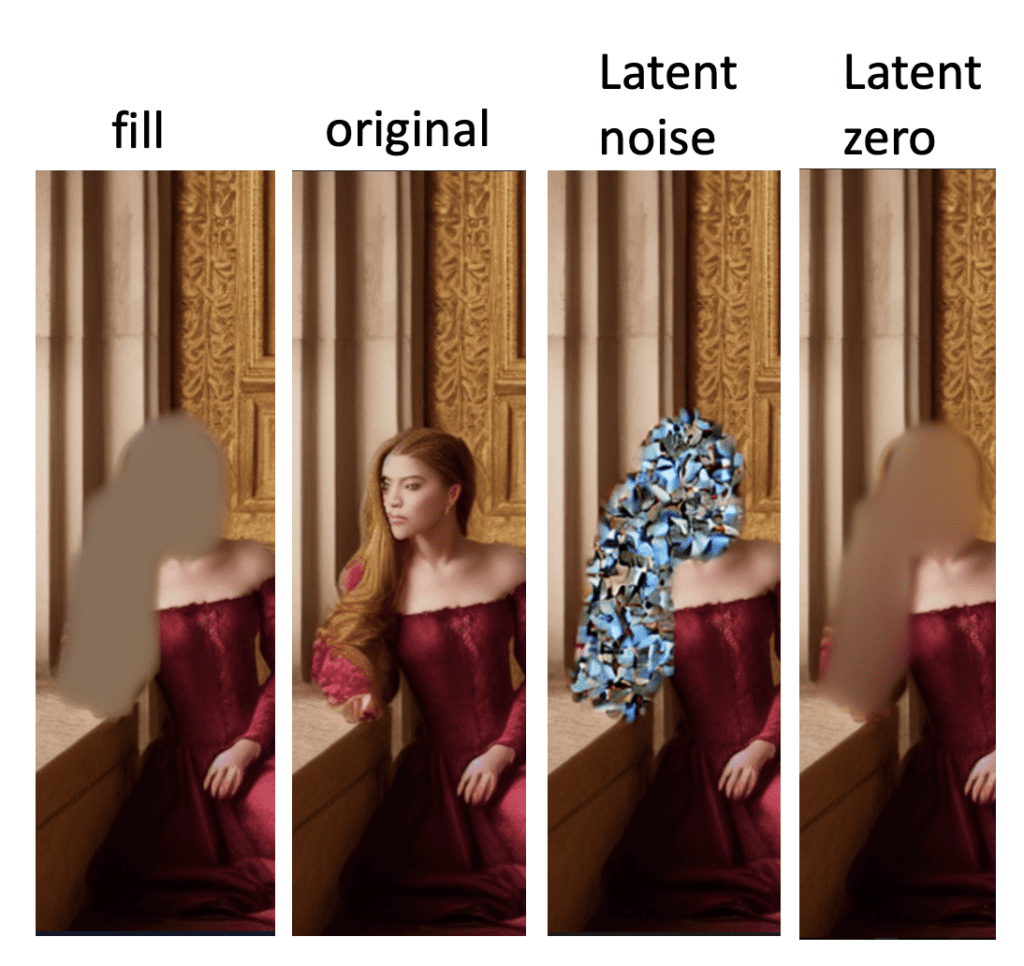
Conteúdo mascarado
O conteúdo mascarado controla como a área mascarada é inicializada.
Preenchimento : Inicializa com uma parte altamente desfocada da imagem original.
Original : Sem modificações.
Ruído latente : área mascarada inicializada com preenchimento e ruído aleatório é adicionado ao espaço latente.
Nada latente : como ruído latente, exceto que nenhum ruído é adicionado ao espaço latente.
Abaixo estão os conteúdos iniciais da máscara antes de quaisquer etapas de amostragem. Isso dá a você uma ideia do que eles são.
Conteúdo mascarado.
Dicas para pintura interna
A pintura interna bem-sucedida requer paciência e habilidade. Aqui estão algumas dicas para usar a pintura interna
Uma pequena área de cada vez.
Manter o conteúdo mascarado no Original e ajustar a intensidade da redução de ruído funciona 90% das vezes.
Experimente o conteúdo mascarado para ver qual funciona melhor.
Se nada funcionar bem dentro das configurações do AUTOMATIC1111, use um software de edição de fotos como Photoshop ou GIMP para pintar a área de interesse com a forma e a cor aproximadas que você queria. Carregue essa imagem e pinte com o conteúdo original.
A construção de prompts é uma habilidade básica que qualquer usuário do Stable Diffusion deve dominar. Ao entender como construir prompts claros e concisos, você pode desbloquear toda a gama de estilos que o Stable Diffusion oferece. Para se destacar na construção de prompts, você deve começar com um assunto específico em mente e adicionar palavras-chave para direcionar para um efeito específico.
A habilidade que você aprenderá neste artigo pode ser aplicada a outros geradores de arte de IA, como o MidJourney.
Se você quiser praticar a construção de prompts, mas ainda não configurou seu Stable Diffusion, você pode usar um gerador de Difusão Estável gratuito online.
Use o criador de prompts para uma abordagem sistemática para criar prompts.
Este post pretende ser seu primeiro curso de prompting. Veja este guia de prompt para técnicas avançadas.
Anatomia de um bom prompt
Esta é uma técnica comprovada para gerar imagens específicas de alta qualidade. Seu prompt deve cobrir a maioria, se não todas, dessas áreas.
Assunto (obrigatório)
Meio
Estilo
Artista
Site
Resolução
Detalhes adicionais
Cor
Iluminação
Assunto
Primeiro, você precisará de uma descrição do assunto com o máximo de detalhes possível. Abaixo está um exemplo.
Prompt (somente assunto):
Uma jovem mulher com vestido azul claro sentada ao lado de uma janela de madeira lendo um livro.
Um erro comum de um iniciante é não descrever a imagem com detalhes suficientes . Que roupa ela usa? Qual é o penteado dela? Esses elementos aparentemente menores podem contribuir significativamente para a imagem geral que está sendo transmitida. Sem especificar esses detalhes, você os deixa abertos para o gerador de IA e pode ficar desapontado com o que obtém.
É uma boa prática incluir um prompt negativo genérico.
Obtivemos a seguinte imagem, que corresponde muito bem ao prompt.
Uma jovem mulher com vestido azul claro sentada ao lado de uma janela de madeira lendo um livro.
Meio
Podemos ser mais específicos. Vamos adicionar um meio , o material em que a obra de arte é criada. Alguns exemplos são pintura digital , fotografia e pintura a óleo . Vamos usar
Medium
Pintura digital
O novo prompt é
Pintura digital de uma jovem com vestido azul claro sentada ao lado de uma janela de madeira lendo um livro
A imagem resultante é
Pintura digital de uma jovem com vestido azul claro sentada ao lado de uma janela de madeira lendo um livro
Você pode ver a imagem mudar de uma fotografia para uma arte digital. É um passo à frente, mas podemos fazer melhor.
Adicionando o resto
Você entendeu a ideia. Vamos adicionar o resto deles
Artist– especificando o artista que criou a arte para orientar o estilo.
por Stanley Artgerm Lau
Website– O nome do site pode ser usado para um gênero específico.
artstation
Resolution– São palavras-chave que controlam a nitidez da imagem.
8k
Additional details– Estas são palavras-chave que são mais como adoçantes, por exemplo, adicionando alguns detalhes interessantes.
Pintura digital de uma jovem mulher com vestido azul claro sentada ao lado de uma janela de madeira lendo um livro, por Stanley Artgerm Lau, artstation, 8k, extremamente detalhado, ornamentado, iluminação cinematográfica, iluminação de borda, vívido
Agora temos esta imagem.
Pintura digital de uma jovem mulher com vestido azul claro sentada ao lado de uma …
Podemos projetar a imagem para obter o estilo desejado adicionando palavras-chave específicas ao prompt.
Dicas para bons prompts
Seja detalhista e específico ao descrever o assunto.
Use vários colchetes () para aumentar sua força e [] para reduzir.
Use um tipo de mídia apropriado consistente com o artista. Por exemplo, fotografia não deve ser usada com van Gogh.
O nome do artista é um modificador de estilo muito forte. Use com sabedoria.
Experimente misturar estilos.
Vá para a seção Fluxos de Trabalho para estudar os prompts de alta qualidade. Use o prompt como ponto de partida se você gostar de uma imagem específica.
Algumas boas palavras-chave para você
Abaixo estão algumas das minhas palavras-chave favoritas e seus efeitos. (Usado com Stable Diffusionv1.4 e v1.5). Aproveite!
Desenhos muito realistas. Bom para usar com pessoas.
Pintura digital
Estilo de arte digital.
Arte conceitual
Estilo de ilustração, 2D.
Ilustração ultra realista
Desenhos muito realistas. Bom para usar com pessoas.
Retrato subaquático
Use com pessoas. Embaixo d’água. Cabelo flutuando.
Steampunk subaquático
Desenhos muito realistas. Bom para usar com pessoas.
Estilo
Essas palavras-chave refinam ainda mais o estilo de arte.
palavra-chave
Observação
hiperrealista
Aumenta os detalhes e a resolução
arte pop
Estilo pop art
Modernista
cor vibrante, alto contraste
arte nova
Adicione ornamentos e detalhes, estilo de construção
Artista
Mencionar o artista no prompt é um efeito forte. Estude o trabalho dele e escolha sabiamente.
palavra-chave
Observação
João Collier
Pintor de retratos do século XIX. Adicione elegância
Stanley Artgerm Lau
Bom para usar com retratos de mulheres, gerar roupas delicadas do século XIX, algum impressionismo
Frida Kahlo
Efeito bastante forte seguindo o estilo de retrato de Kahlo. Às vezes resulta em moldura de imagem
John Cantor Sargento
Bom para usar com retratos de mulheres, gerar roupas delicadas do século XIX, algum impressionismo
Alfonso Mucha
Pintura de retrato 2D no estilo de Alphonse Mucha
Site
Mencionar um site de arte ou fotografia tem um efeito forte, provavelmente porque cada site tem seu gênero de nicho.
palavra-chave
Observação
pixiv
Estilo anime japonês
pixabay
Estilo de fotografia comercial
artstation
Ilustração moderna, fantasia
Resolução
palavra-chave
Observação
unreal engine
3D muito realista e detalhado
foco nítido
Aumentar a resolução
8k
Aumentar a resolução, embora possa fazer com que pareça mais falso. Torna a imagem mais parecida com a de uma câmera e mais realista
muito
Renderização 3D ideal para objetos, paisagens e construções.
Iluminação
palavra-chave
Observação
iluminação de borda
luz na borda de um objeto
iluminação cinematográfica
Um termo genérico para melhorar o contraste usando luz
raios crepusculares
luz do sol rompendo a nuvem
Detalhes adicionais
Adicione detalhes específicos à sua imagem.
palavra-chave
Observação
dramático
filmado de um ângulo baixo
seda
Adicione seda à roupa
expansivo
Fundo mais aberto, assunto menor
foto em ângulo baixo
foto tirada de um ângulo baixo
raios de deus
luz do sol rompendo a nuvem
psicodélico
cor viva com distorção
Cor
Adicione um esquema de cores adicional à imagem.
palavra-chave
Observação
ouro iridescente
Ouro brilhante
prata
Cor prata
vintage
efeito vintage
Resumo
Passamos pela estrutura básica de um bom prompt. Isso deve ser usado como um guia e não como uma regra. O modelo Stable Diffusion é muito flexível. Deixe-o surpreender você com alguma combinação criativa de palavras-chave!
Quer aprender Stable Diffusion AI? Este guia para iniciantes é destinado aos novatos e sem experiência com Stable Diffusion, Flux ou outros geradores de imagem por IA. Ele dará a você uma visão geral do Stable Diffusion/Flux AI e por onde começar.
Estou dentro! Como começar a usar Stable Diffusion e Flux AI?
Geradores online
Execute no seu PC
GUI avançada
O que o Stable Diffusion pode fazer?
Gerar imagens a partir de texto
Gerar uma imagem a partir de uma imagem
Edição de fotos
Faça vídeos
Como criar um bom prompt?
Regras básicas para criar bons prompts
Seja detalhado e específico
Use palavras-chave poderosas
Quais são esses parâmetros e devo alterá-los?
Quantas imagens devo gerar?
Maneiras comuns de corrigir defeitos em imagens
Restauração Facial
Corrigindo pequenos artefatos com pintura interna
O que são modelos personalizados?
Qual modelo devo usar?
Como treinar um novo modelo?
Avisos negativos
Como fazer impressões grandes com Stable Diffusion?
Como controlar a composição da imagem?
Imagem para imagem
ControlNet (Rede de controle)
Regional prompting (Incitação regional)
Profundidade para imagem
Gerando assuntos específicos
Pessoas realistas
Animais
O que é Unstable Diffusion?
Próximo passo
O que é Stable Diffusion?
Stable Diffusion AI é um modelo de difusão latente para gerar imagens de IA. As imagens podem ser foto realistas, como aquelas capturadas por uma câmera, ou artísticas, como se fossem produzidas por um artista profissional.
A melhor parte é que ele é gratuito. Você pode executá-lo no seu PC ou pode usá-lo online por uma taxa.
Falarei sobre as opções para usar Stable Diffusion e Flux na parte final deste artigo. Mas se você não puder esperar, pegue o Guia de Início Rápido no Stable Diffusion e mergulhe de cabeça.
Como usar a difusão estável?
Tudo o que você precisa é de um prompt que descreva uma imagem . Por exemplo:
casa de gengibre, diorama, em foco, fundo branco, torrada, cereal crocante
A Difusão Estável transforma esse prompt em imagens como as abaixo.
Você pode gerar quantas variações quiser a partir do mesmo prompt.
Qual é a vantagem da difusão estável?
Existem serviços de geração de texto para imagem semelhantes, como o DALLE e o MidJourney da OpenAI. Por que Stable Diffusion? As vantagens do Stable Diffusion AI são:
Código aberto: muitos entusiastas criaram ferramentas e modelos gratuitos.
Projetado para computadores de baixo consumo: é gratuito ou barato de usar.
O Stable Diffusion AI é gratuito?
O Stable Diffusion é gratuito para uso quando executado em suas próprias máquinas Windows ou Mac . Um serviço online custará uma taxa modesta.
Estou dentro! Como começar a usar Stable Diffusion e Flux AI?
Há muitas maneiras de usar modelos de IA de difusão estável e fluxo. Você precisa decidir:
Executar no seu PC ou usar um serviço online?
Qual interface gráfica você deseja usar?
Geradores online
Para iniciantes absolutos, recomendo usar um gerador online gratuito . Você pode começar a gerar sem o incômodo de configurar as coisas.
Gere algumas imagens e veja se a IA é sua praia.
Execute no seu PC
A melhor opção de PC é executar o Windows com uma placa GPU Nvidia . A maioria dos modelos de IA são otimizados para GPUs Nvidia. As GPUs AMD estão começando a ganhar força, mas espere passar por obstáculos para usá-las. Quanto mais VRAM sua GPU tiver, menos problemas você precisará
Você precisa de um Apple Silicon (M1/M2/M3/M4) para rodar em um Mac.
GUI avançada
A desvantagem dos geradores online gratuitos é que as funcionalidades são bastante limitadas.
Use uma GUI (Graphical User Interface) avançada se você já não as usa mais. Uma gama completa de ferramentas está à sua disposição. Para citar algumas:
Imagem para imagem (img2img) transforma uma imagem em outra usando IA de difusão estável.
Abaixo está um exemplo de como transformar meu desenho de uma maçã em um desenho foto realista. ( Tutorial)
Imagem para imagem gera uma imagem com base em uma imagem de entrada e um prompt.
3. Edição de fotos
Você pode usar inpainting para regenerar parte de uma imagem realou de IA . Isso é o mesmo que a nova função de preenchimento generativo do Photoshop, mas grátis.
4. Faça vídeos
Existem duas maneiras principais de fazer vídeos com Stable Diffusion: (1) a partir de um prompt de texto e (2) a partir de outro vídeo.
Deforum é uma maneira popular de fazer um vídeo a partir de um prompt de texto. Você provavelmente já viu um deles nas mídias sociais. Parece com isso:
Este é um tópico mais avançado. É melhor dominar texto para imagem e imagem para imagem antes de mergulhar nele.
Como criar um bom prompt?
Há muito o que aprender para elaborar um bom prompt . Mas o básico é descrever seu assunto com o máximo de detalhes possível. Certifique-se de incluir palavras-chave poderosas para definir o estilo.
Usar um gerador de prompts é uma ótima maneira de aprender um processo passo a passo e palavras-chave importantes. É essencial para iniciantes aprender um conjunto de palavras-chave poderosas e seus efeitos esperados. Isso é como aprender vocabulário para um novo idioma. Você também pode encontrar uma pequena lista de palavras-chave e notas aqui.
Um atalho para gerar imagens de alta qualidade é reutilizar prompts existentes. Vá para a coleção de prompts, escolha uma imagem que você goste e roube o prompt! A desvantagem é que você pode não entender por que ele gera imagens de alta qualidade. Leia as notas e altere o prompt para ver o efeito.
Como alternativa, use sites de coleta de imagens como o PlaygroundAI . Escolha uma imagem que você goste e remixe o prompt. Mas pode ser como encontrar uma agulha em um palheiro para um prompt de alta qualidade.
Trate o prompt como um ponto de partida. Modifique para atender às suas necessidades.
Regras básicas para criar bons prompts
Duas regras: (1) Seja detalhado e específico e (2) use palavras-chave poderosas.
Seja detalhado e específico
Embora a IA avance a passos largos, a Stable Diffusion ainda não consegue ler sua mente. Você precisa descrever sua imagem com o máximo de detalhes possível.
Digamos que você queira gerar uma imagem de uma mulher em uma cena de rua. Um prompt simplista uma mulher na rua fornece uma imagem como esta:
Prompt sem detalhes
Bem, você pode não querer gerar uma avó, mas isso tecnicamente corresponde ao seu prompt. Você não pode culpar a Stable Diffusion…
Então, em vez disso, você deveria escrever mais.
uma jovem senhora, olhos castanhos, mechas no cabelo, sorriso, vestindo traje casual de negócios elegante, sentada do lado de fora, rua tranquila da cidade, iluminação de borda
Quer trapacear? Assim como fazer lição de casa, você pode usar o ChatGPT para gerar prompts!
Quais são esses parâmetros e como devo alterá-los?
A maioria dos geradores online permite que você altere um conjunto limitado de parâmetros. Abaixo estão alguns importantes:
Tamanho da imagem : O tamanho da imagem de saída. O tamanho padrão é 512×512 pixels. Mudá-lo para o tamanho retrato ou paisagem pode ter um grande impacto na imagem. Por exemplo, useo tamanho retrato para gerar uma imagem de corpo inteiro.
Etapas de amostragem: Use pelo menos 20 etapas. Aumente se você vir uma imagem borrada.
Escala CFG : O valor típico é 7. Aumente se quiser que a imagem siga mais o prompt.
Valor semente: -1 gera uma imagem aleatória. Especifique um valor se quiser a mesma imagem.
Quais são esses parâmetros e como devo alterá-los?
Quantas imagens devo gerar?
Você deve sempre gerar várias imagens ao testar um prompt.
Eu gero de 2 a 4 imagens por vez ao fazer grandes mudanças no prompt para que eu possa acelerar a busca. Eu geraria 4 por vez ao fazer pequenas mudanças para aumentar a chance de ver algo utilizável.
Alguns prompts funcionam apenas metade do tempo ou menos. Então, não descarte um prompt com base em uma imagem.
Maneiras comuns de corrigir defeitos em imagens
Quando você vê imagens de IA impressionantes compartilhadas em mídias sociais, há uma boa chance de que elas tenham passado por uma série de etapas de pós-processamento. Vamos abordar algumas delas nesta seção.
Restauração Facial
Esquerda: Imagens originais. Direita: Após restauração da face.
É bem conhecido na comunidade de artistas de IA que Stable Diffusion não é bom em gerar rostos. Muitas vezes, os rostos gerados têm artefatos.
Frequentemente usamos modelos de IA de imagem que são treinados para restaurar faces, por exemplo, CodeFormer , que AUTOMATIC1111 GUI tem suporte integrado. Veja como ativá-lo.
Você sabia que há uma atualização para os modelos v1.4 e v1.5 para consertar os olhos? Veja como instalar um VAE.
Corrigindo pequenos artefatos com pintura interna
É difícil obter a imagem que você quer na primeira tentativa. Uma abordagem melhor é gerar uma imagem com boa composição. Então repare os defeitos com inpainting.
Abaixo está um exemplo de uma imagem antes e depois do inpainting. Usar o prompt original para inpainting funciona 90% das vezes.
Esquerda: Imagem original com defeitos. Direita: O rosto e o braço são corrigidos por inpainting.
Existem outras técnicas para consertar as coisas. Leia mais sobre como consertar problemas comuns .
O que são modelos personalizados?
Os modelos oficiais lançados pela Stability AI e seus parceiros são chamados de modelos base . Alguns exemplos de modelos base são Stable Diffusion1.4, 1.5, 2.0e 2.1.
Modelos personalizados são treinados a partir dos modelos base. Atualmente, a maioria dos modelos é treinada a partir da v1.4 ou v1.5. Eles são treinados com dados adicionais para gerar imagens de estilos ou objetos específicos.
Somente o céu é o limite quando se trata de modelos personalizados. Pode ser estilo anime, estilo Disney ou o estilo de outra IA. Você escolhe.
Abaixo está uma comparação de 5 modelos diferentes.
Você pode pensar que deveria começar com os modelos v2 mais novos. As pessoas ainda estão tentando descobrir como usar os modelos v2. Imagens do v2 não são necessariamente melhores que as do v1.
Houve uma série de modelos SDXL lançados: SDXL beta , SDXL 0.9 e o mais recente SDXL 1.0.
Recomendo usar os modelos v1.5e SDXL 1.0 se você for novo no Stable Diffusion.
Como treinar um novo modelo?
Uma vantagem de usar Stable Diffusion é que você tem controle total do modelo. Você pode criar seu próprio modelo com um estilo único se quiser. Duas maneiras principais de treinar modelos: (1) Dreamboothe (2) embedding.
O Dreambooth é considerado mais poderoso porque ele ajusta o peso de todo o modelo. Os embeddings deixam o modelo intocado, mas encontram palavras-chave para descrever o novo assunto ou estilo.
Você pode experimentar o caderno Colab no artigo do dreambooth.
Avisos negativos
Você coloca o que quer ver no prompt. Você coloca o que não quer ver no prompt negativo. Nem todos os serviços de Stable Diffusion suportam prompts negativos. Mas é valioso para modelos v1 e essencial para modelos v2. Não faz mal para um iniciante usar um prompt negativo universal. Leia mais sobre prompts negativos:
Como fazer impressões grandes com difusão estável?
A resolução nativa do Stable Diffusion é 512×512 pixels para modelos v1. Você NÃO deve gerar imagens com largura e altura que desviem muito de 512 pixels. Use as seguintes configurações de tamanho para gerar a imagem inicial.
Imagem de paisagem : Defina a altura para 512 pixels. Defina a largura para mais alto, por exemplo, 768 pixels (proporção de aspecto 2:3)
Imagem de retrato : Defina a largura para 512 pixels. Defina a altura para mais alto, por exemplo, 768 pixels (proporção de aspecto 3:2)
Se você definir a largura e a altura iniciais muito altas, verá assuntos duplicados.
O próximo passo é aumentar a escala da imagem. A GUI AUTOMATIC1111 gratuita vem com alguns upscalers de IA populares.
Leia este tutorial para obter um guia para iniciantes sobre upscalers de IA.
A tecnologia Stable Diffusion está melhorando rapidamente. Existem algumas maneiras.
Imagem para imagem
Você pode pedir ao Stable Diffusion para seguir aproximadamente uma imagem de entrada ao gerar uma nova. É chamado de imagem para imagem . Abaixo está um exemplo de uso de uma imagem de entrada de uma águia para gerar um dragão. A composição da imagem de saída segue a entrada.
Imagem para imagem – originalImagem para imagem – modificadaImagem para imagem
Rede de controle
O ControlNet usa similarmente uma imagem de entrada para direcionar a saída. Mas ele pode extrair informações específicas, por exemplo, poses humanas. Abaixo está um exemplo de uso do ControlNet para copiar uma pose humana da imagem de entrada.
Imagem de entrada
Além de poses humanas, o ControlNet pode extrair outras informações, como contornos.
Regional Prompter
Você pode especificar prompts para certas partes de imagens usando uma extensão chamada Regional Prompter . Essa técnica é muito útil para desenhar objetos somente em certas partes da imagem.
Abaixo está um exemplo de como colocar um lobo no canto inferior esquerdo e caveiras no canto inferior direito.
Depth-to-image é outra maneira de controlar a composição por meio de uma imagem de entrada. Ele pode detectar o primeiro plano e o segundo plano da imagem de entrada. A imagem de saída seguirá o mesmo primeiro plano e segundo plano. Abaixo está um exemplo.
Imagem de entrada
Gerando assuntos específicos
Pessoas realistas
Você pode usar Stable Diffusion para gerar pessoas realistas em estilo de foto. Vamos ver alguns exemplos.
Pessoas realistas
Tudo se resume a usar o prompt certo e um modelo especial treinado para produzir humanos realistas no estilo de foto. Aprenda mais no tutorial para gerar pessoas realistas .
Animais
Animais são temas populares entre os usuários do Stable Diffusion.
Aqui estão alguns exemplos.
Animais
Leia o tutorial para gerar animais para aprender como.
O que é difusão instável?
Unstable Diffusion é uma empresa que desenvolve modelosde Stable Diffusion para pornografia de IA. Eles viraram manchetes quando sua campanha de arrecadação de fundos no Kickstarter foi encerrada. Até agora, eles não divulgaram nenhum modelo publicamente.
A empresa não tem relação com a Stability AI, a empresa que lançou o Stable Diffusion AI.
Próximo passo
Então, você concluiu o primeiro tutorial do Guia do Iniciante!
 Personagens Consistentes
1 × R$50.00
Personagens Consistentes
1 × R$50.00